
In the early 1990s I was privileged enough to be immersed in the world of technology during the exciting period that gave birth to the World Wide Web, and I can honestly say I managed to completely miss those first stirrings of the information revolution in favour of CD-ROMs, a piece of technology which definitely didn’t have a future. I’ve written in the past about that experience and what it taught me about confusing the medium with the message, but today I’m returning to that period in search of something else. How can we regain some of the things that made that early Web good?
We All Know What’s Wrong With The Web…
It’s likely most Hackaday readers could recite a list of problems with the web as it exists here in 2024. Cory Doctrow coined a word for it, enshitification, referring to the shift of web users from being the consumers of online services to the product of those services, squeezed by a few Internet monopolies. A few massive corporations control so much of our online experience from the server to the browser, to the extent that for so many people there is very little the touch outside those confines.
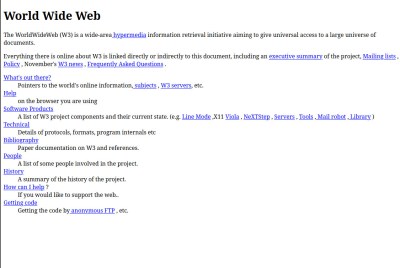
Contrasting the enshitified web of 2024 with the early web, it’s not difficult to see how some of the promise was lost. Perhaps not the web of Tim Berners-Lee and his NeXT cube, but the one of a few years later, when Netscape was the new kid on the block to pair with your Trumpet Winsock. CD-ROMs were about to crash and burn, and I was learning how to create simple HTML pages.
The promise then was of a decentralised information network in which we would all have our own websites, or homepages as the language of the time put it, on our own servers. Microsoft even gave their users the tools to do this with Windows, in that the least technical of users could put a Frontpage Express web site on their Personal Web Server instance. This promise seems fanciful to modern ears, as fanciful perhaps as keeping the overall size of each individual page under 50k, but at the time it seemed possible.
With such promise then, just how did we end up here? I’m sure many of you will chip in in the comments with your own takes, but of course, setting up and maintaining a web server is either hard, or costly. Anyone foolish enough to point their Windows Personal Web Server directly at the Internet would find their machine compromised by script kiddies, and having your own “proper” hosting took money and expertise. Free stuff always wins online, so in those early days it was the likes of Geocities or Angelfire which drew the non-technical crowds. It’s hardly surprising that this trend continued into the early days of social media, starting the inevitable slide into today’s scene described above.
…So Here’s How To Fix It
If there’s a ray of hope in this wilderness then, it comes in the shape of the Small Web. This is a movement in reaction to a Facebook or Google internet, an attempt to return to that mid-1990s dream of a web of lightweight self-hosted sites. It’s a term which encompases both lightweight use of traditional web tehnologies and some new ones designed more specifically to deliver lightweight services, and it’s fair to say that while it’s not going to displace those corporations any time soon it does hold the interesting prospect of providing an alternative. From a Hackaday perspective we see Small Web technologies as ideal for serving and consuming through microcontroller-based devices, for instance, such as event badges. Why shouldn’t a hacker camp badge have a Gemini client which picks up the camp schedule, for example? Because the Small Web is something of a broad term, this is the first part of a short series providing an introduction to the topic. We’ve set out here what it is and where it comes from, so it’s now time to take a look at some of those 1990s beginnings in the form of Gopher, before looking at what some might call its spiritual successors today.
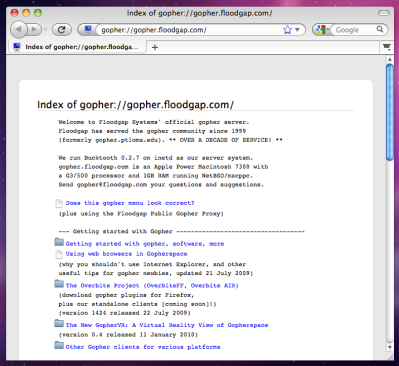
It’s odd to return to Gopher after three decades, as it’s one of those protocols which was for most of us immediately lost as the Web gained traction. Particulrly as at the time I associated Gopher with CLI base clients and the Web with the then-new NCSA Mosaic, I’d retained that view somehow. It’s interesting then to come back and look at how the first generation of web browsers rendered Gopher sites, and see that they did a reasonable job of making them look a lot like the more texty web sites of the day. In another universe perhaps Gopher would have evolved further to something more like the web, but instead it remains an ossifed glimpse of 1992 even if there are still a surprising number of active Gopher servers still to be found. There’s a re-imagined version of the Veronica search engine, and some fun can be had browsing this backwater.
With the benefit of a few decades of the Web it’s immediately clear that while Gopher is very fast indeed in the days of 64-bit desktops and gigabit fibre, the limitations of what it can do are rather obvious. We’re used to consuming information as pages instead of as files, and it just doesn’t meet those expectations. Happily though Gopher never made those modifications, there’s something like what it might have become in Gemini. This is a lightweight protocol like Gopher, but with a page format that allows hyperlinking. Intentionally it’s not simply trying to re-implement the web and HTML, instead it’s trying to preserve the simplicity while giving users the hyperlinking that makes the web so useful.
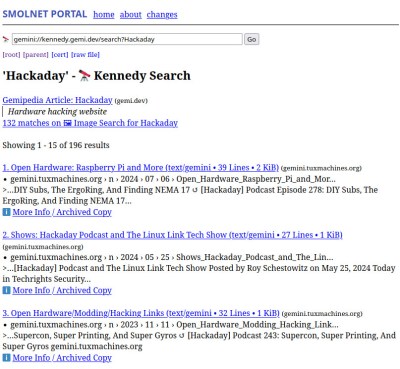
The great thing about Gemini is that it’s easy to try. The Gemini protocol website has a list of known clients, but if even that’s too much, find a Gemini to HTTP proxy (I’m not linking to one, to avoid swamping someone’s low traffic web server). I was soon up and running, and exploring the world of Gemini sites. Hackaday don’t have a presence there… yet.
We’ve become so used to web pages taking a visible time to load, that the lightning-fast response of Gemini is a bit of a shock at first. It’s normal for a web page to contain many megabytes of images, Javascript, CSS, and other resources, so what is in effect the Web stripped down to only the information is unexpected. The pages are only a few K in size and load in effect, instantaneously. This may not be how the Web should be, but it’s certainly how fast and efficient hypertext information should be.
This has been part 1 of a series on the Small Web, in looking at the history and the Gemini protocol from a user perspective we know we’ve only scratched the surface of the topic. Next time we’ll be looking at how to create a Gemini site of your own, through learning it ourselves.